AI的试错智慧:解密强化学习

“术解”专题——从碎片化阅读中获得人工智能领域的“原来如此”
我们从问题出发,深入浅出地剖析,揭示原理,融入思考
往期:
01 猜词之外
我们与 ChatGPT 这类 AI 对话时,常惊叹于它们的对答如流和善解人意。它们不仅知识渊博,还能遵循指令,甚至拒绝不当请求。但一个有趣的问题是:我们知道它们的基础是“预测下一个词”,可仅仅擅长文本接龙,如何能保证它们成为有用、懂规矩的对话伙伴呢?AI 是如何跨越从“猜词机器”到“靠谱助手”这道鸿沟的?答案的关键,指向一种被称为强化学习 (Reinforcement Learning, RL) 的强大训练范式。
02 试错与奖励
强化学习的核心思想,其实非常贴近我们生物的本能学习方式。想象婴儿学步,跌跌撞撞,最终掌握平衡;或者宠物在训练中,因正确的动作获得零食奖励,逐渐学会指令。这其中没有“标准答案”可供背诵,学习依赖的是在与环境的互动中不断尝试,并根据结果的好坏(奖励或惩罚)来调整行为。
在 RL 的世界里,我们有几个基本角色:智能体 (Agent),也就是学习者(比如 AI 模型);环境 (Environment),即 Agent 互动和影响的对象;智能体根据感知到的状态 (State),选择执行动作 (Action);环境会给予一个奖励 (Reward) 作为反馈;智能体的目标是学习一套最优的策略 (Policy)——即在不同状态下如何选择动作的行为准则——以最大化长期累积的奖励。与看着标准答案学习的监督学习不同,RL 强调从经验中学习,在探索与试错中寻找通往目标的最佳路径。

03 AI 学规矩
预训练后的语言模型,知识丰富但行为可能不受约束。为了让它成为一个“有用、无害、诚实”的助手,我们需要对其进行“对齐”。通常,会先进行监督微调 (Supervised Fine-tuning, SFT),让模型初步学会按照人类期望的对话格式进行回应。但这还不够,人类的偏好复杂多样,难以用固定的答案覆盖。
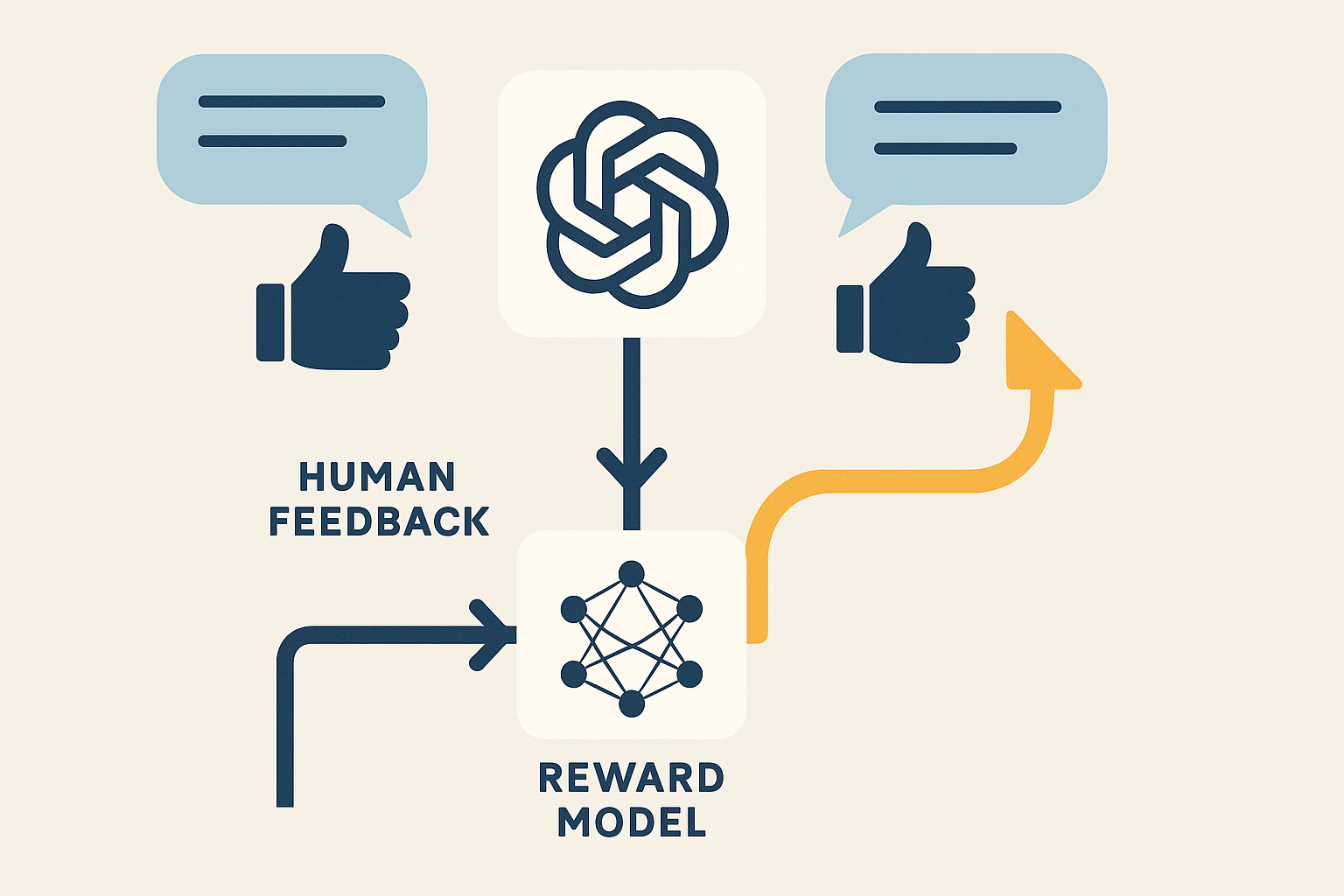
这时,强化学习就派上了大用场,特别是基于人类反馈的强化学习 (RLHF)。它的巧妙之处在于,利用人类对模型不同输出的偏好排序,训练出一个奖励模型 (Reward Model)。这个奖励模型就像一个“品味裁判”,能评估 AI 生成内容的质量,输出一个奖励分数。然后,以大模型为智能体,对话过程为环境,奖励模型的分数为奖励信号,通过 RL 算法(如 PPO)不断优化模型的策略,使其更倾向于生成人类喜欢(即奖励分数高)的回答。这样,模型就学会了“投其所好”,行为更加符合人类的价值观和期望。
DeepSeek 团队在训练其 R1 模型时,就采用了名为群体相对策略优化 (Group Relative Policy Optimization, GRPO) 的新技术。相比传统方法,GRPO 不需要额外的价值模型,而是通过比较“一组”候选回答的好坏来计算相对优势,直接优化策略。这种方法在提升训练效率和稳定性,尤其是在激发模型的复杂推理能力方面,展现出了潜力。当然,像 R1-Zero 这样的纯 RL 训练也面临挑战,比如需要后续步骤(如少量 SFT)来改善输出的可读性。这些探索都在推动着 RL 技术更好地服务于 AI 对齐。
04 不止于聊天
强化学习的威力远不止于“调教”聊天机器人。它作为一个通用的决策学习框架,正在驱动着许多前沿领域的发展,尤其是在**AI Agent(智能体)**的浪潮中扮演着核心角色。
AI Agent 的目标是能够自主理解目标、制定计划、执行复杂任务。 这天然地需要 Agent 具备在环境中持续学习、做出一系列决策、并根据反馈调整行为的能力——这正是强化学习的用武之地。RL 为训练 Agent 在动态环境中达成长期目标提供了理论基础和算法工具。无论是让 Agent 学会使用外部工具(如搜索引擎、计算器),还是在虚拟或现实世界中导航和操作,RL 都不可或缺。可以说,强化学习是构建真正自主的 AI Agent 的关键引擎之一。

-
机器人学: 训练机器人掌握精密的灵巧操作(如叠衣服、系鞋带),或在复杂地形中自主导航。
-
系统优化: 优化数据中心能耗、推荐系统的用户长期参与度、金融算法交易策略等。
-
游戏 AI: 从 AlphaGo 到更复杂的即时战略游戏,RL 不断刷新着机器智能的上限。
当然,RL 的应用也面临挑战,如样本效率低(需要大量尝试)、奖励函数设计困难、模拟与现实的迁移差距等。如何高效、安全、可靠地应用和扩展 RL(Scaling RL),依然是重要的研究方向。
05 我们的镜像
回看强化学习的核心——试错、反馈、优化策略以最大化累积奖励——这与我们人类自身的学习和成长过程何其相似?我们蹒跚学步,探索世界,从成功中获得喜悦(正奖励),从失败中吸取教训(负奖励),逐渐形成自己的行为模式和价值观。
不同的是,AI 的奖励函数通常是人类为特定任务设计的(比如 RLHF 中由人类偏好定义的奖励模型)。而人类,似乎生活在一个没有预设“终极奖励函数”的世界里。我们在漫长的一生中,通过与环境、与他人的互动,不断探索、体验、反思,似乎也在自主地寻找和塑造着属于自己的“内在奖励函数”——定义什么是重要的,什么是有意义的,什么能带来长期的幸福感和成就感。
我思: 从这个角度看,强化学习的研究不仅推动着 AI 技术的发展,也在某种程度上提供了一个观察和反思“学习”与“价值形成”本质的独特视角。当我们努力让 AI 通过 RL 对齐人类价值观时,或许也在促使我们更深入地思考:人类自身的价值观是如何形成和演化的?我们希望传递给未来智能体的,究竟是怎样的“奖励信号”?
06 原来如此
当我们惊叹于大模型能像一个助手一样与我们对话时,要明白这并非一蹴而就。在掌握了海量知识(预训练)之后,是强化学习等关键技术扮演了“行为导师”的角色。通过巧妙地引入反馈机制(如人类偏好),RL 让 AI 在与世界的互动中学会了分辨“好”与“坏”,优化了自身的行为策略,从而弥合了从“预测文本”到“有用交互”的关键鸿沟。
强化学习赋予了 AI 一种超越简单模式匹配的、面向目标的、适应性的学习能力。它让 AI 不仅拥有知识,更朝着拥有“智慧”(知道如何运用知识达成目标)迈出了重要一步。理解 RL,就是理解 AI 如何在试错中成长,在反馈中“学乖”,并逐渐塑造出我们今天所见的、日益强大的能力。