从加尔定律看人工智能的演化路线
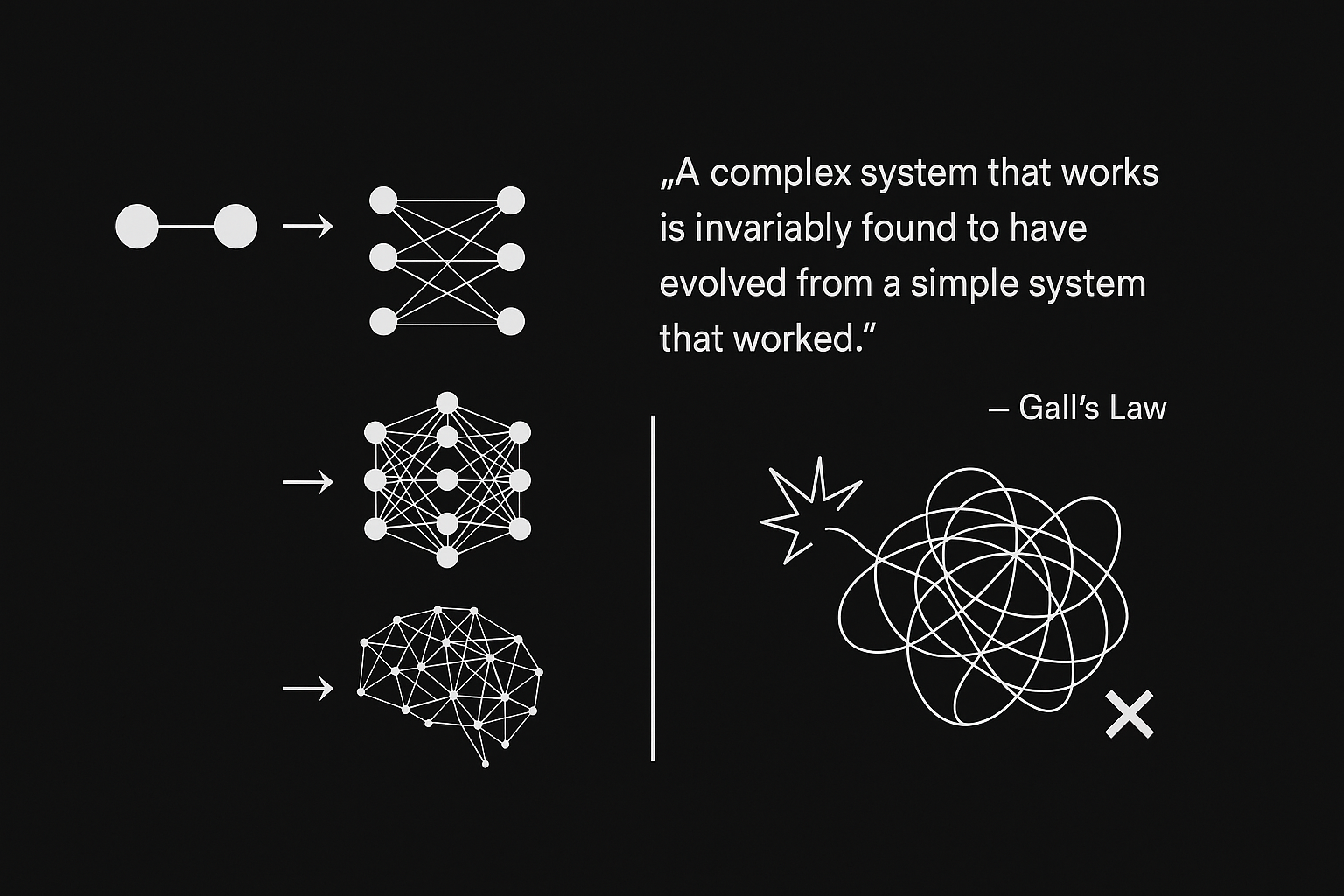
加尔定律(Gall's Law)指出:
一个能够正常运作的复杂系统,必然起源于一个能够正常运作的简单系统。 而试图从零构建的复杂系统,几乎注定无法正常工作,也无法通过事后修补让它变得可行。
这一定律原本用于描述系统设计中的“演化优于规划”,但放在人工智能的发展轨迹中,却显得格外贴切。
01 神经网络的演化
人工智能,特别是深度学习的发展,很好地体现了从简单系统逐步演化到复杂系统的路径。
- 从最早的MP模型(1943)到感知机(1958),尽管能力有限,但验证了“模拟神经元”这一基本构想是可行的。
- 到80年代,多层感知机与反向传播算法的提出,为更复杂的网络训练提供了技术基础。
- 进入2000年代,卷积神经网络(CNN)和循环神经网络(RNN)带来了实用化的突破。
- 2012年,AlexNet 凭借深层网络和GPU加速,引爆了深度学习浪潮。
- 后续的发展更为惊人:ResNet(2015)解决了深层模型退化问题,Transformer(2017)引入注意力机制与序列建模新范式,彻底改变了NLP乃至整个AI领域。
每一个阶段,都是在已有成功结构的基础上迭代优化,而非从头重造轮子。Transformer 本身也不是“从天而降”的架构,其前身包括 Seq2Seq 模型(2014)、Bahdanau 注意力机制(2014)、编码器-解码器结构等。
越深入了解人工智能发展史,越能感受到这是必然的技术爆炸,日积月累的成果。伴随的硬件能力的提升带来算力倍增,算法的改进、数据的必然性膨胀,一切为scaling law准备。
02 从零构建的反例
相比之下,日本在80年代发起的“第五代计算机系统”计划,则提供了一个违反加尔定律的典型反例。
当时,为了赶超美国的AI技术,日本政府和企业试图绕过传统冯·诺依曼架构,直接构建基于逻辑推理和知识表示的“智能系统”,完全脱离已有架构和经验。
然而,尽管投入巨大,这一尝试最终成果寥寥,未能形成任何实际可持续的技术路径。它试图“从零构建一个复杂系统”,违背了加尔定律的演化原则,因此失败或许也是注定的。
03 强化学习是演化中的下一步
强化学习(RL)正在成为语言模型发展的新焦点,但这也不是一种“推翻现有架构”的革命,而是演化的自然延续。
Claude 开发团队的核心成员 Sholto Douglas 近期在采访中表示:
未来 6 到 12 个月,我们非常关注扩大强化学习 (RL) 的规模,并探索这将把我们带向何方。我预计,因此会看到极其快速的进展。不需要再投入更多数量级的预训练规模。事实证明,强化学习是行之有效的,而且这些模型到 2027 年将能够达到“即插即用型远程工作者”的能力。
之前OpenAI研究员姚顺雨一篇文章表示AI进入下半场,说:
RL 通常被认为是 AI 的“终极形态”,毕竟从理论上,它能够保证在 game( 所有在封闭环境中,有明确输赢的博弈任务。)中取胜,而在实践上,几乎所有 superhuman 水平的 AI 系统(比如 AlphaGo)都离不开 RL 的支撑。
强化学习的引入,在原有架构基础上的进一步演化、微调和行为优化。这种做法,本质上依然遵循着加尔定律。
04 智能的提升
我们或许会不断看到“颠覆Transformer”的声音,但回顾 AI 发展历史我们发现:真正有效的进步,总是在已有系统基础上的渐进式演化。现有的一些模型架构已经是Transformer基础上进行改进的,甚至与其他架构融合,深入底层优化。
就像加尔定律所揭示的,**能够正常工作的复杂系统,不是凭空设计出来的,而是从一个能够工作的简单系统,逐步生长出来的。**期待强化学习进一步验证这些。
智能的提升仍有很长的路可以走,我眼中的“智能”:完成某种复杂目标的能力。